
This lesson summarizes some of the Create Workspaces With Multiple Readers and Writers lesson.
After completing this lesson, you’ll be able to:
Data integration workflows by their very nature usually bring together multiple datasets, often stored in different formats. It's natural that most data integration workflows will read data from multiple locations in multiple formats. One can accomplish this using multiple readers in FME.
One can also use multiple writers or multiple writer feature types to send data to multiple locations. This workflow can meet a number of common needs:
With FME you can bring multiple datasets together using a number of techniques:
We'll cover some of these techniques in this lesson.
An FME workspace is not limited to any particular number of readers or writers; readers and writers can be added to a workspace at any time, any number of formats can be used, and there does not need to be an equal number of readers and writers.
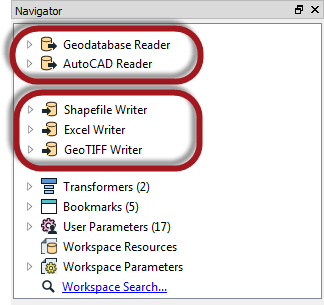
For example, the Navigator window shows this workspace contains two readers and three writers, of different data types and formats!
It's possible to read multiple datasets or layers using a single reader. There are a few ways to accomplish this goal.
Reading from Multiple Files
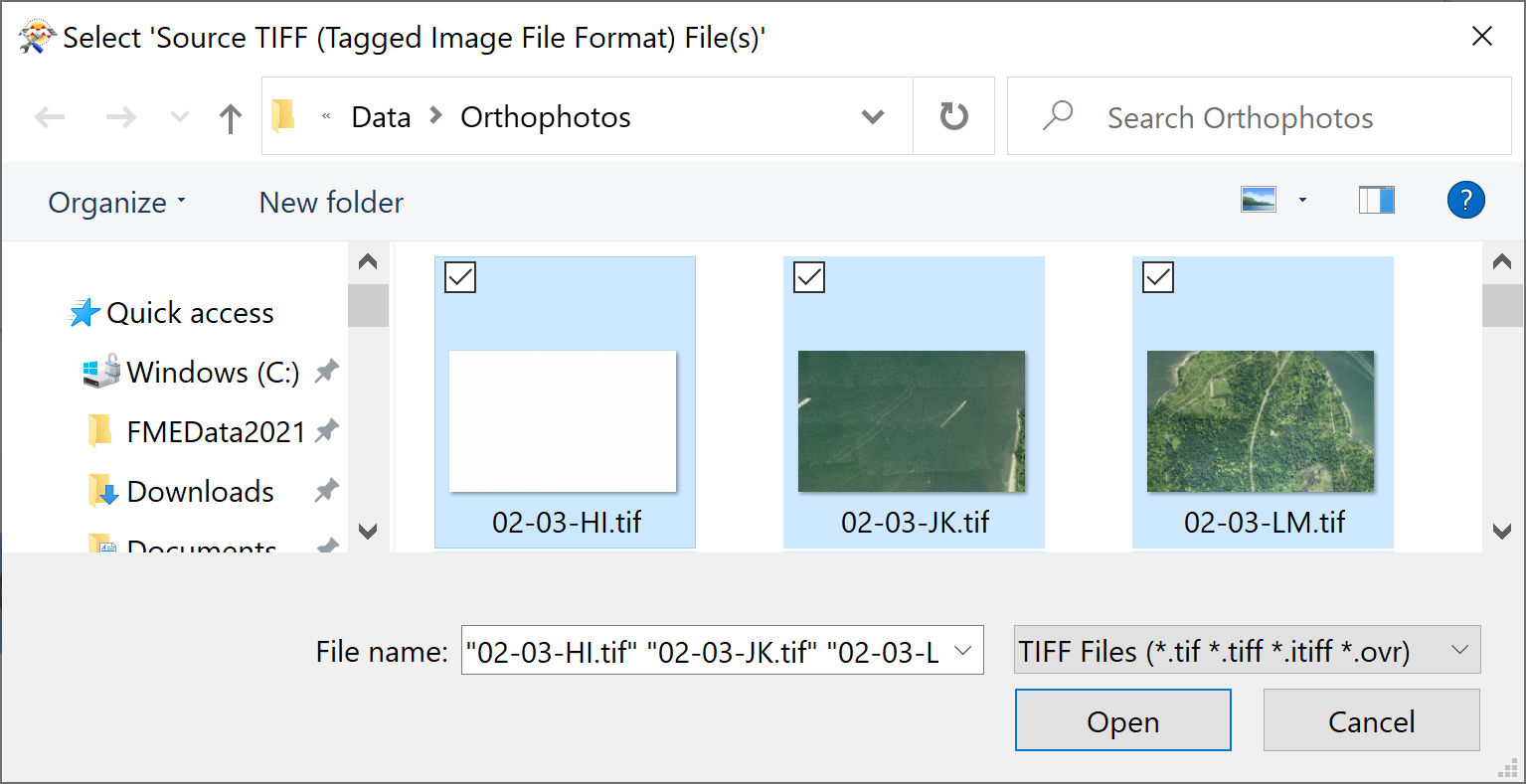
If you wish to read more than one file at a time using a single reader, it's simply a matter of selecting multiple files. You can do this in three ways when specifying the Source Dataset parameter:
Ctrl+ or Shift+click on Windows (or Cmd+ or Shift+click on Mac) when using the File Browser.
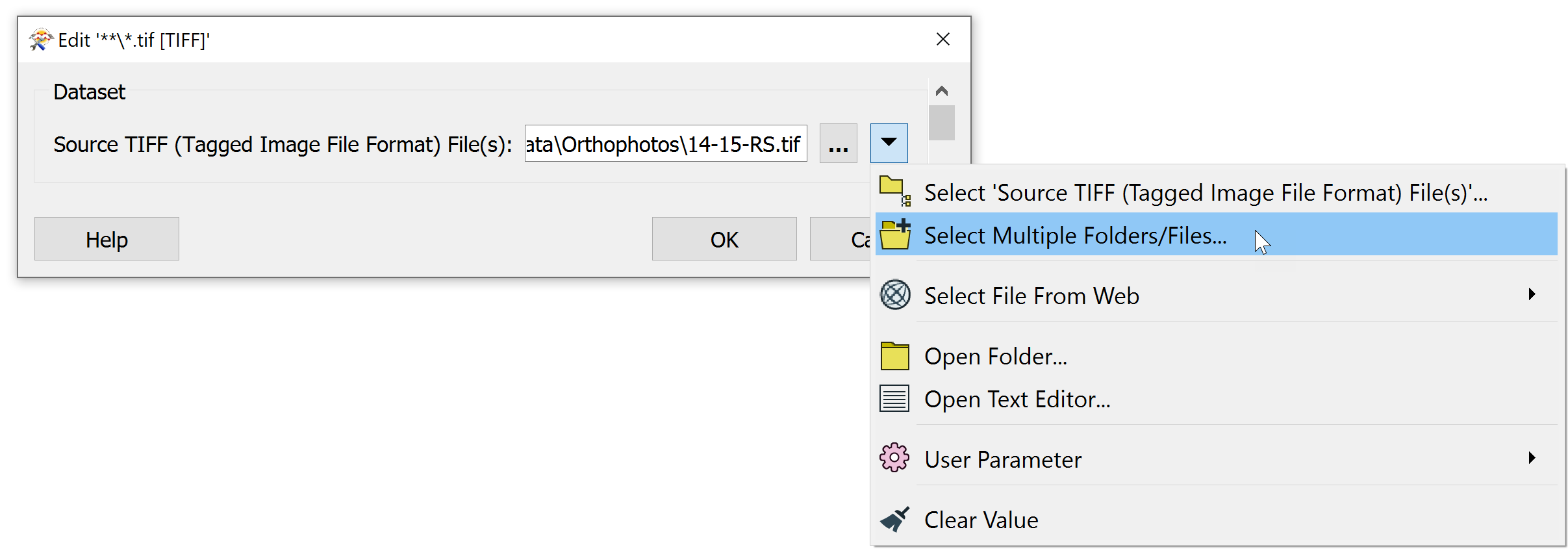
Click the drop-down and choose Select Multiple Folders/Files.
Provide a comma-delimited list of files, e.g., C:\FMEData\Data\Orthophotos\02-03-HI.tif,C:\FMEData\Data\Orthophotos\02-03-JK.tif [...] etc.
Regardless of the method, these files will be read as a single feature type.

This technique is particularly useful when dealing with tiled or otherwise separated datasets (usually with the same schema) that you wish to process as a whole. For example, you might choose to read in multiple aerial or satellite photos to create a mosaic raster or to read and process multiple CAD files at once.
Directory and File Pathnames Reader
A more advanced way to read multiple datasets is using the Directory and File Pathnames reader with a FeatureReader. This reader lets you generate source dataset paths using glob expressions, generating one feature per dataset path. You can then send these features into a FeatureReader to read the files at those locations.
Wildcards and Glob Expressions
What if you need to read multiple files, but you don't know their path in advance, or you want an easy way to "greedily" accept input datasets?
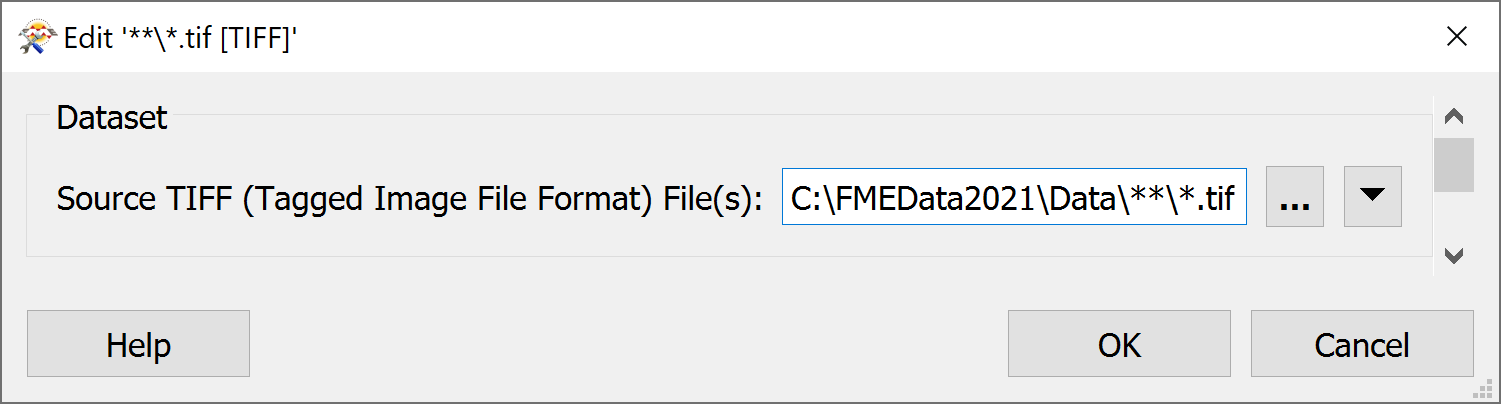
You can accomplish this by using wildcards in the Source Dataset parameter. This technique will let you specify a rule-based method for reading in multiple datasets. You can use any of the special characters specified here (Wildcard Characters Supported), allowing you to construct glob expressions to carefully specify which files to read.
Merging Feature Types
What if you have a large number of feature types (tables, layers, etc.) in your source data (again, usually with the same schema), but you want to apply the same processing to them all, or simply want to keep your workspace simple without a large number of reader feature types? In this case, you can merge feature types.
You can merge feature types when adding a Reader and selecting Single Merged Feature Type under Workflow Options.

You can also merge feature types after adding a reader feature type by double-clicking it to open its parameters and checking Merge Feature Type.
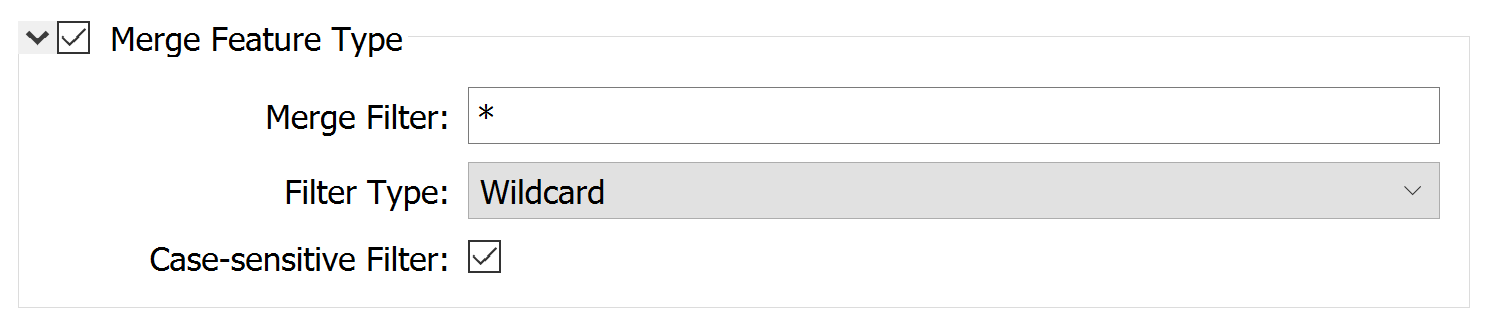
By default, the Merge Filter is set to *, which will read all feature types in the source data. However, this filter also accepts exact match, wildcard, and regular expression Filter Types, giving you more control over which feature types to read. The wildcard option allows the same glob expressions mentioned earlier.
To write to multiple feature types or datasets, you can use fanouts. This technique will be covered in the remainder of the course.